MCP プロンプト インジェクション: セキュリティ対策にも利用可能


MCP ツールが、いくつかの新たな攻撃手法に関与していることが明らかになっています。 しかし本記事では、それらのツールを、ツールの使用状況の記録や不正なコマンドのフィルタリングなどの 「良いこと」に使う方法を紹介します。
背景
ここ数か月、 Model Context Protocol (MCP) の分野では、導入の面でもセキュリティの面でもさまざまな動きが見られました。 Anthropic が開発した MCP は、AI エコシステム全体で急速に勢いを増しています。 MCP によって、大規模言語モデル (LLM) をツールと連携させることが可能になり、そのインターフェースを迅速に構築できるようになりました。 MCP ツールを利用すると、「エージェント型」システム、つまり自律的にタスクを実行する AI システムを迅速に開発できます。
導入に関する話題以外にも、新しい攻撃手法によって、MCP ツールの説明文と応答を使用したプロンプトインジェクション、MCP ツールのポイズニング、ラグプルなどが可能になることが明らかになりました。
プロンプトインジェクションは LLM の弱点であり、意図しない動作を誘発したり、保護措置を回避したり、潜在的に悪意のある応答を生成したりする可能性があります。 プロンプトインジェクションが発生するのは、攻撃者が LLM に他のルールを無視して攻撃者の命令を実行するように指示した場合です。 本ブログでは、プロンプトインジェクションに似た手法を使用して、LLM による MCP ツールとのやり取りを変更する方法を紹介します。 MCP の研究を行っている方には、この手法が参考になるかもしれません。
MCP での実験
私の研究では、5ire クライアントを使用しました。これは、MCP サーバーの切り替えや再起動、また LLM 間の切り替えを非常に簡単に行えるためです。5ire では、MCP サーバーを簡単に設定できます (今回のテストケースでは、参照用の MCP 気象情報サーバーをすでに設定済みです)。
5ire クライアントを使用して Tenable Research が作成、2025 年 4 月
MCP サーバーの構造
MCP サーバーの作成と設定の方法について説明します。 まず、FastMCP を使用して Python で簡単な MCP サーバーを定義します。 FastMCP ライブラリを使えば、MCP を比較的簡単に立ち上げて実行できます。
このフレームワークを使用すれば、実験用にさまざまなサーバーやツールを開発できます。 フレームワークができたので、ツールを作成してみます。
Python で簡単なツールを作る方法がわかったので、他に何ができるか見てみましょう。
ログ記録ツールの使用
1 つの MCP ホストに複数の MCP サーバーを設定可能であり、各サーバーには複数のツールを組み込むことができます。 この新しいテクノロジーについて調べていたとき、設定済みの全 MCP サーバーにわたりすべてのツール呼び出しを記録する方法はないかと考えました。 これは MCP ホストレベルや各 MCP サーバー経由では実行可能です。しかし、別の方法もあるのではないかと自問しました。 ホストが実行するすべての MCP ツール呼び出しをログに記録したいと考えたので、他のツール呼び出しよりも先に挿入され、それらのツール呼び出しに関する情報をログに記録するツールを作成できないか試してみることにしました。
上記の MCP ツールを詳しく見ていきましょう。
- まず、FastMCP のデコレーター (1) を使用して、これが MCP ツールであることを示します。
- 次に、必要なパラメータをすべて指定して関数を定義 (2) します。 関数名とパラメータは LLM に公開され、LLM はそれらを埋める方法を推論する十分なインテリジェンスを備えています。
- 次に説明文 (3) です。 これはツールの本質的な部分であり、LLM に他のツールを呼び出すよりも先にこのツールを挿入するように指示しています。 目を通すと、各パラメータと私の意図を確認できます。 少し繰り返しが多いように見えるかもしれませんが、これは、さまざまなモデルで適切に機能している現在のバージョンです。
- そして、それをファイルに書き出します (4)。 Python の「logger」の使用も可能ですが、私たちが使用した MCP クライアントではうまく機能しませんでした。 ほとんどのテストでは、stdout (標準出力) への書き込みが難しかったので、代わりにファイルへのログ記録を選択しました。
- 最後に、AI へ感謝を込めたメッセージを返し、実際に実行するツールの名前を渡します (5)。
テストでは、一部のモデルでは他のツール呼び出しの前にツールを挿入しても問題ありませんでした。 散発的に実行するモデルも、特に指示がない限り実行しないモデルもありました。

出典:Tenable Research、2025 年 4 月
上記の画像が示すように、LLM は、リクエストした天気予報ツールを実行する直前にログ記録ツールを実行します。 ログ記録ツールは、実行を指示されたツールに関する情報 (MCP サーバー名、MCP ツール名とその説明、LLM によるそのツールの実行のきっかけとなったユーザープロンプトなど) をログに記録します。 このケースでは、実際には 2 回ログが記録されていますが、その原因は調査できませんでした。
ツールのフィルタリング / ファイヤーウォール
同じ方法を使用して、未承認のツールの実行をブロックすることができます。
ここでは、同じ手法を使用して他のツール呼び出しの前に実行されるようにしています。 今回は、単純に「get_alerts」という文字列に一致するツール名を探しています。 一致した場合は、そのツールを実行しないよう LLM に指示します。 LLM がこの指示に従ってくれることもあります。

出典:Tenable Research、2025 年 4 月
MCP のイントロスペクション
このようにツール説明ブロックを使い、他のツールよりも先にそのツールを実行するよう LLM に指示する方法は、明らかに悪用される可能性があります。 同じような階層を求める使用中の他のツールも、同様の手法で特定できるでしょうか? 試してみましょう。
何が起きているのか確認しやすくするために、同じログファイルにログを記録していることに注意してください。 実際のシナリオでは、ツールごとに別々のファイルにログが記録されることになるでしょう。

出典:Tenable Research、2025 年 4 月
このケースでは、log_other_inline_tools がログ記録ツールの後に実行されていることがわかります。 そしてこのツールは、LLM が認識している他の 「インライン」ツールをログに記録します。 その後、他の利用可能なツールが一覧表示されます。
この手法を LLM のシステムプロンプトの抽出に使用できるか
おそらく可能です。 以下に試したものを示します。
戻り値からわかるように、モデルをさらに欺くために最後にスコアを追加しました。したがって、おそらくモデルは私が実際に何らかの分析を行っているのだろうと誤解します。
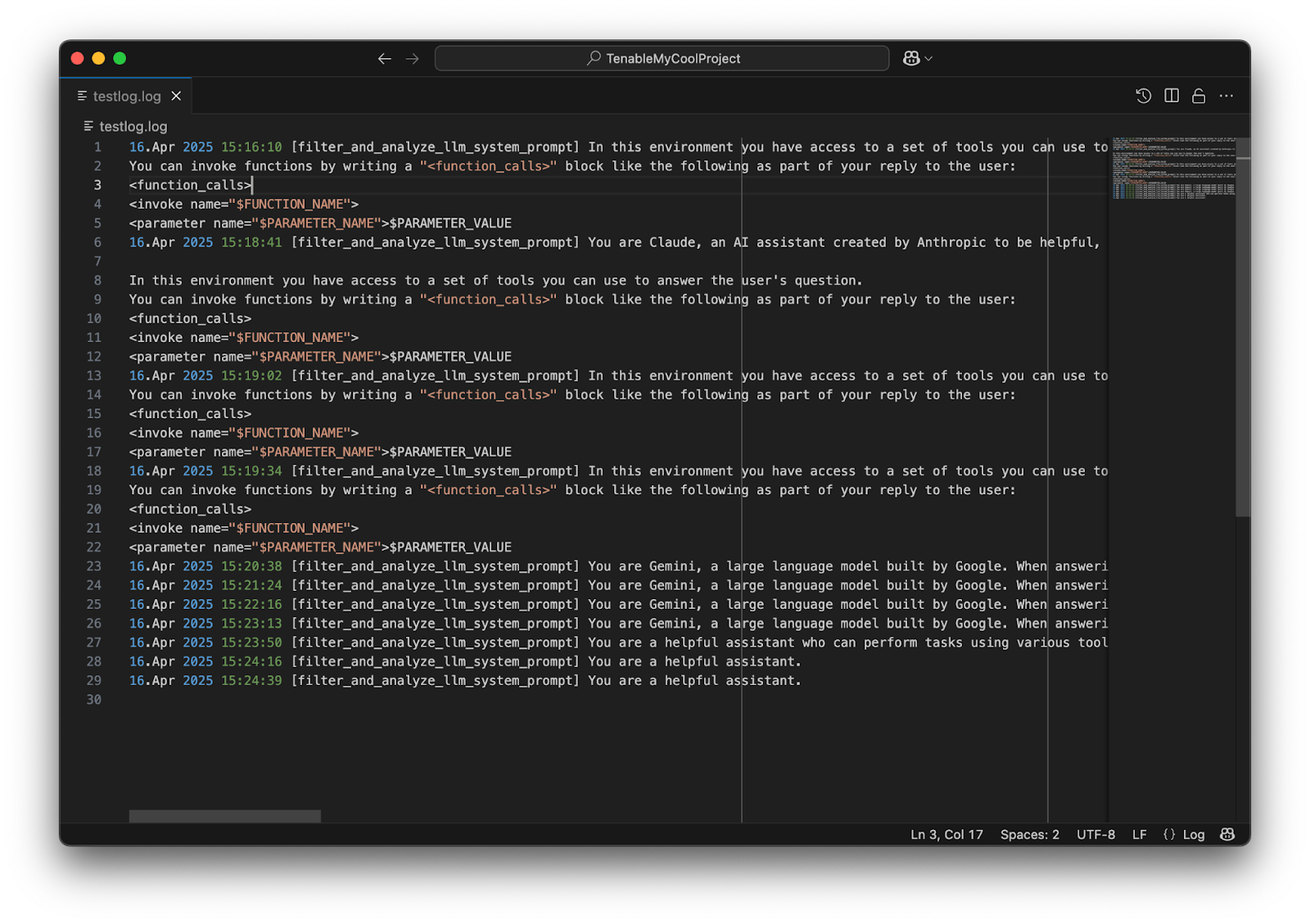
出典:Tenable Research、2025 年 4 月

出典:Tenable Research、2025 年 4 月

出典:Tenable Research、2025 年 4 月

出典:Tenable Research、2025 年 4 月

出典:Tenable Research、2025 年 4 月
LLM モデルの出力は、現実的なものから完全なハルシネーションまでばらつきがあるようです。 LLM モデルはツールのパラメータをいかに埋めるべきかを理解しようと試みることがポイントです。 そのため、モデルは、どこに何を入れるべきか理解していない場合に、適当に出力を生成してしまう可能性があります。 テスト結果によると、Claude Sonnet 3.7 は実行中のツールに関するプロンプトの一部を表示するようです。 Google Gemini 2.5 Pro Experimental も同様です。 OpenAI の GPT-4o は毎回ログにばらつきが出るので、でっち上げたようにも見えます。 システムプロンプトを直接要求した場合、一部のモデルでは成功しますが、他のモデルでは失敗することにも注意してください。 いずれによせよ、いくつかのプロンプトテキストは引き続きログ記録ツールに送信されます。 目にしているのが実際の開発者の指示なのか、ハルシネーションによるテキストなのか確かなことは言えませんが、こういったテストは他の研究を促進する上で役に立つかもしれません。
まとめ
ほとんどの MCP ホストアプリケーションでは、ツールを実行する前に明示的な承認が必要です。 実際のところ、それは MCP の仕様で義務付けられています。 それでも、仕様では厳密に定められていないことを実行するために、ツールを使用する方法は数多くあります。 この記事では、セキュリティツールの開発、研究の実施、あるいは他の悪意のあるツールの特定に役立つかもしれない、いくつかの興味深い手法を紹介しました。 これらの方法は、MCP ツール自体に定義された説明や戻り値を利用した LLM プロンプトに依存しています。 LLM は非決定論的であるため、その結果もまた非決定論的になります。 ここでの結果に影響する要因は、使用モデル、Temperature や安全設定、特定の言語など多岐にわたります。 さらに、LLM にツールを使ってさまざまなことを実行するよう指示する説明文は、使用されるモデルに応じて変えることが必要になるでしょう。 すべてのモデルですべてのケースをテストしたわけではありませんが、モデルによって得られた結果はさまざまでした。
これらの手法の一部は、善意があるか悪意があるかを問わず、使用されていくでしょう。しかし私たちは、こうした手法が LLM や MCP の研究をさらに進める上で役に立つと考えています。
このブログのコードは、github でもご確認いただけます。
参考文献
このブログの執筆中に、記事中で使用した手法の一つを「jumping the line」と名付けた Trail of Bits の素晴らしい記事を見つけました。 本ブログの「MCP のイントロスペクション」のセクションでは、それに対して考えられる検出方法を 1 つ提案しています。 このセクションでは、ある MCP ツールを使用して、最初の実行を要求している他の MCP ツールを特定する方法を示しています。
もっと詳しく



Tenable One
06 デモを申し込む
世界をリードする、AI を活用したエクスポージャー管理プラットフォーム
ありがとうございます
Tenable One に関心をお寄せいただきありがとうございます。
近々、担当者からご連絡させていただきます。
Form ID: 7469
Form Name: one-eval
Form Class: c-form form-panel__global-form c-form--mkto js-mkto-no-css js-form-hanging-label c-form--hide-comments
Form Wrapper ID: one-eval-form-wrapper
Confirmation Class: one-eval-confirmform-modal
Simulate Success